


Key terms and techs in the DeepSeek era
Equip yourself with the basics and embrace AI.

The arrival of DeepSeek started a new wave of AI revolution. Coming months, the whole AI industry will adjust and we are see costs models are shifting. This post is to help more people to understand the terms and be more ready to digest new developments.
Neural Networks :
Imagine a child learning to walk. They stumble and fall many times, and with each fall, their brain figures out which muscle movements work best. This trial-and-error process helps them gradually improve their balance and coordination.
In a similar way, a neural network learns by repeatedly trying different approaches to solve a problem. It "remembers" past mistakes and uses that experience to refine its strategy over many iterations, much like a child learning to walk through repeated practice.
Reinforcement Learning (RL) :
Baby walking the good result is well defined and can be measured. In reasoning or natural language problems, we need another way to educate neural network. Imagine you ask a computer to solve the same problem millions of times. Each time, it might come up with a different answer. In reinforcement learning, the computer gets rewarded when its answer is close to the correct one. The “correct” answer might be defined by human experts or even by another AI system.
Here’s how it works in simple terms:
Reward System: The computer receives a reward for good answers and a penalty for bad ones. This reward system helps the computer learn which actions lead to better outcomes.
Evolution Over Time: Think of the computer’s learning process as evolving over thousands of generations. In each generation, the computer tries out random settings (or parameters) to solve the problem. The settings that result in higher rewards "survive" and are refined in the next round.
In short, reinforcement learning is like a trial-and-error process where the computer gradually learns the best way to solve a problem by remembering and favoring the actions that lead to rewards.
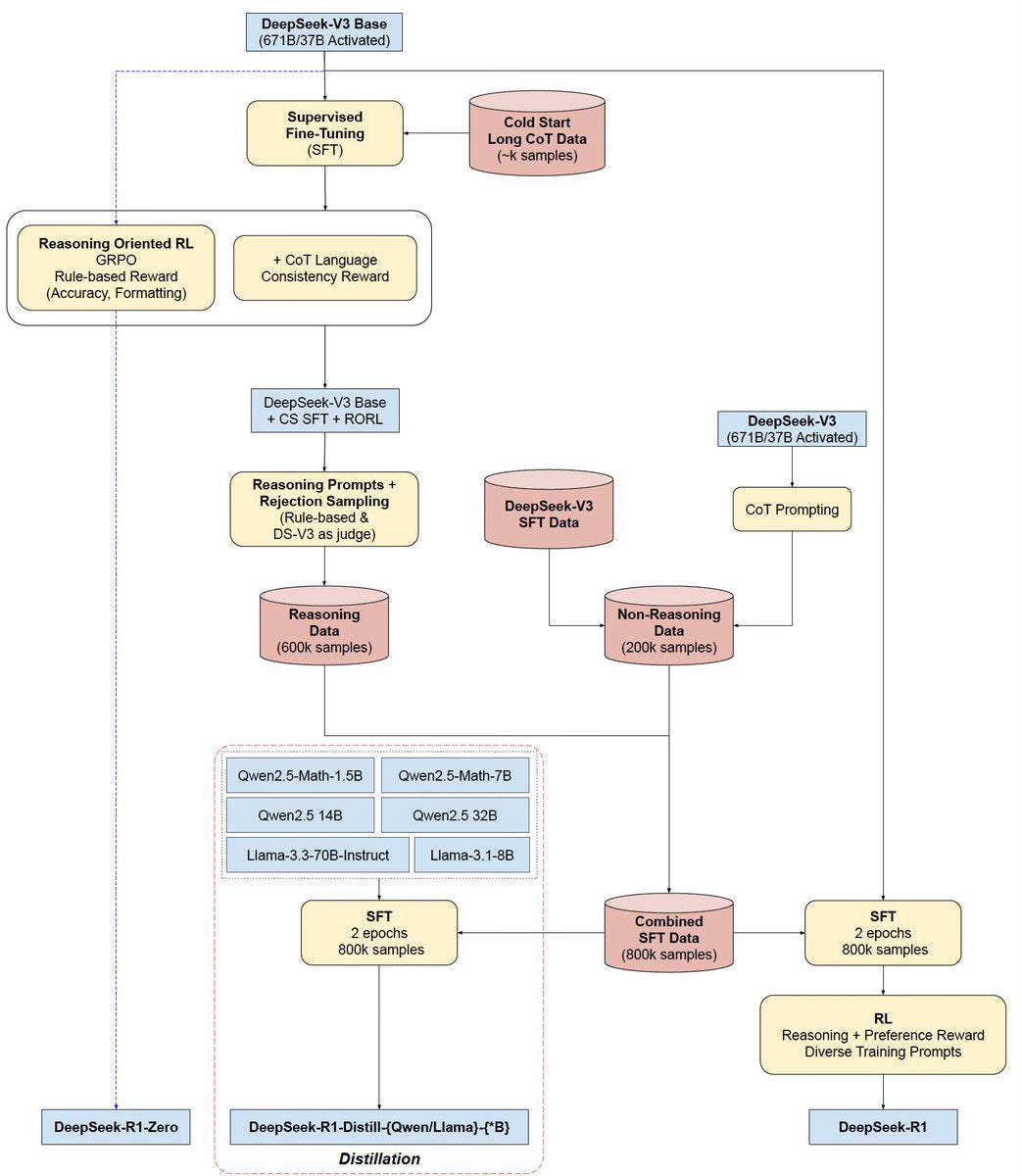
DeepSeek team breakthrough is a new reinforcement learning that is rule based namely Group Relative Policy Optimization (GRPO). This is from the DeepSeek team and it is totally different from openAI, or Meta Llama.
Group Relative Policy Optimization (GRPO)
Training advanced AI models isn't just about having powerful GPUs; acquiring high-quality, well-labeled data is another major expense. Obtaining such data at scale is challenging. Companies like Scale AI have addressed this by employing large teams to label data, which has contributed to their billion-dollar valuations.
DeepSeek engineers have introduced a new reinforcement learning approach called Group Relative Policy Optimization (GRPO). This method is designed to enhance the model's ability to solve math and science problems with clear, deterministic answers. With GRPO, the AI model effectively learns from its own experiences by following a set of rules defined by DeepSeek engineers. Using a base model known as DeepSeek V4, GRPO improves the model’s reasoning capabilities, resulting in a new model called DeepSeek-R1-Zero. The aim of this approach is to reduce future dependence on external data labeling services like Scale AI.
DeepSeek-R1-Zero :
DeepSeek-R1-Zero is a pioneering AI model built on DeepSeek V3. While it shows enhanced reasoning skills, its responses can be hard to follow and sometimes mix different languages, making it less suitable for direct commercial applications. Nonetheless, it remains a valuable resource for research and further AI training.
DeepSeek-R1 :
To address readability and usability issues, DeepSeek-R1 undergoes Supervised Fine-Tuning (SFT). This process involves training the model on curated examples to align its responses with the conversational styles and formats expected by everyday users. The result is a model that delivers clear, user-friendly answers and is available for use at chat.deepseek.com.
Supervised fine-tuning (SFT) :
When you need a language model to produce responses in a specific format, tone, or style, supervised fine-tuning is a practical solution. By providing the model with well-defined examples of questions and answers, it learns to mimic the desired output style, ensuring consistency and clarity in its responses.
In summary, GRPO and SFT are key innovations by DeepSeek that enhance both the reasoning and communication abilities of their AI models, paving the way for more autonomous and accessible AI solutions.
Subscribe and we will talk about vLLM , TSP and the cost impact in next post.
DeepSeek 的到來掀起了一股新的 AI 革新浪潮。未來幾個月,整個 AI 產業都將進行調整,而我們也在推出全新的轉變。這篇文章旨在幫助更多人理解相關術語,並更好地準備迎接新發展。
神經網絡 :
想像一個孩子正在學習走路。他們會多次絆倒和跌倒,而每次跌倒後,大腦都會分析哪些肌肉運動最有效。這種試錯過程幫助他們逐步改善平衡和協調能力。
類似地,神經網絡通過反覆嘗試不同方法來解決問題。它會「記住」過去的錯誤,並利用這些經驗在多次迭代中完善策略,就像孩子通過重複練習學習走路一樣。
強化學習(RL) :
嬰兒學步的「良好結果」是明確定義且可量化的。但在推理或自然語言問題中,我們需要另一種教育神經網絡的方式。想像讓電腦嘗試解決同一個問題數百萬次,每次都可能產生不同答案。在強化學習中,當電腦的答案接近正確時會獲得獎勵,而「正確答案」可能由人類專家甚至另一個AI系統定義。
簡單來說運作原理是:
獎勵機制:電腦因正確答案獲得獎勵,錯誤答案則受懲罰。這套機制幫助電腦學習哪些行動能產生更好結果。
時間演化:將電腦的學習過程視為歷經數千代的演化。每一代中,電腦嘗試隨機參數設置來解決問題,獲得較高獎勵的參數設置會「存活」並在下一輪優化。
簡言之,強化學習就像試錯過程,電腦通過記住並強化能帶來獎勵的行動,逐步學習解決問題的最佳方式。
深度求索(DeepSeek)團隊的突破是一種基於規則的新型強化學習方法——群組相對策略優化(GRPO)。這項技術完全有別於OpenAI或Meta Llama的架構。
群組相對策略優化(GRPO)
訓練先進AI模型不僅需要強大GPU,獲取高品質標註數據更是巨額成本。大規模獲取此類數據極具挑戰性,Scale AI等公司正是通過組建龐大數據標註團隊達成這點,這也是其估值達數十億美元的重要原因。
DeepSeek工程師開發了名為GRPO的新型強化學習方法,專門提升模型在數學與科學等具明確答案領域的解題能力。通過GRPO,AI模型能基於工程師設定的規則框架,有效從自身經驗中學習。以DeepSeek V4為基礎模型,GRPO強化了推理能力,最終形成DeepSeek-R1-Zero模型。此方法旨在減少未來對Scale AI等外部數據標註服務的依賴。
DeepSeek-R1-Zero :
基於DeepSeek V3架構的開創性AI模型。雖然展現出強化推理能力,但其回答邏輯跳躍性強且混雜多種語言,較難直接商業應用,仍是重要的研究與AI訓練資源。
DeepSeek-R1 :
為改善可讀性與實用性,DeepSeek-R1經過監督式微調(SFT)。此過程通過精選範例訓練,使模型輸出符合日常用戶期待的對話風格與格式,最終呈現清晰易用的回答,可於chat.deepseek.com實際體驗。
監督式微調(SFT) :
當需要語言模型以特定格式、語氣或風格回應時,監督式微調是實用解決方案。通過提供明確定義的問答範例,模型能學習模仿期望的輸出模式,確保回答的一致性和清晰度。
總結而言,GRPO與SFT是DeepSeek的關鍵創新,同步提升AI模型的推理與溝通能力,為實現更自主、易用的AI解決方案鋪路。
訂閱並關注我們,下篇將深入解析vLLM、TSP技術及其成本影響。
src file of the map https://www.reddit.com/r/LocalLLaMA/comments/1i66j4f/deepseekr1_training_pipeline_visualized/